Processing Kafka records on virtual threads

In another blog post, we have seen how you can implement a CRUD application with Quarkus to utilize virtual threads. The virtual threads support in Quarkus is not limited to REST and HTTP. Many other parts support virtual threads, such as gRPC, scheduled tasks, and messaging. In this post, we will see how you can process Kafka records on virtual threads, increasing the concurrency of the processing.
Processing messages on virtual threads
The Quarkus Reactive Messaging extension supports virtual threads.
Similarly to HTTP, to execute the processing on a virtual thread, you need to use the @RunOnVirtualThread annotation:
@Incoming("input-channel")
@Outgoing("output-channel")
@RunOnVirtualThread
public Fraud detect(Transaction tx) {
// Run on a virtual thread
}The processing of each message runs on separate virtual threads.
So, for each message from the input-channel, a new virtual thread is created (as seen in this blog post, virtual thread creation is cheap).
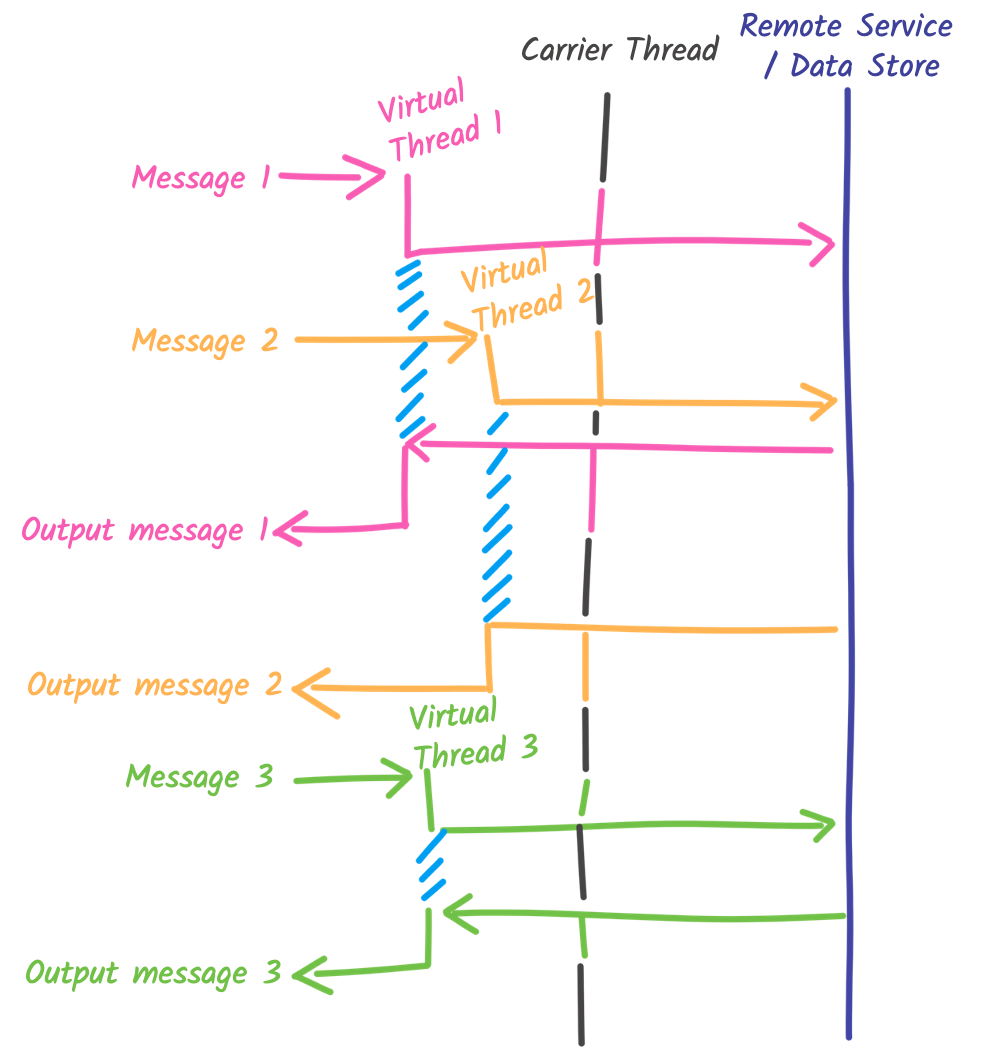
This execution model can be used with any Quarkus reactive messaging connector, including AMQP 1.0, Apache Pulsar, and Apache Kafka.
The concurrency of this processing is no longer limited by the number of worker threads, as it would with the @Blocking annotation.
Thus, this novel execution model simplifies the development of highly concurrent data streaming applications.
As we will see later, such high-level concurrency can cause problems.
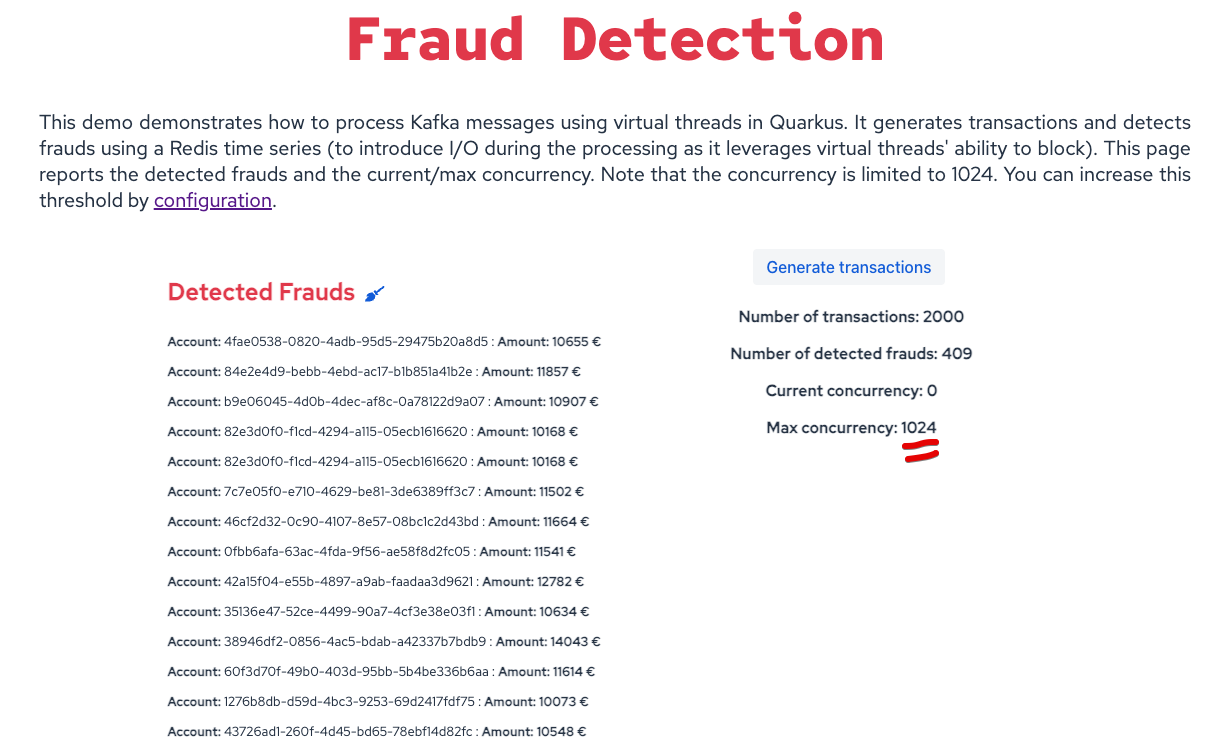
To keep this concurrency controllable, Quarkus limits the number of concurrent message processing to 1024 (This default value is configurable).
One of the main benefits of this limit is preventing the application from polling millions of messages, which would be very expensive in terms of memory.
Without this limit, a Kafka application would poll all the records from the assigned topics-partitions and consume a large amount of memory.
Also, you may wonder why we do not use virtual threads by default. The reasons have been explained in a previous blog post. There are limitations that can make virtual threads dangerous. You need to make sure your virtual threads usage is safe before using it. We will see a few examples in this post.
Processing Kafka records on virtual threads
To illustrate how to process Kafka records on virtual threads, let’s consider a simple application. This application is a fake fraud detector. It analyzes banking transactions, and if the transaction amount for a given account in a given period of time reaches a threshold, we consider there is fraud. The code is available in this GitHub repository. Of course, you can use more complex detection algorithms, and even use AI/ML. In this case, we use the Redis time series commands inefficiently to introduce more I/O than necessary. It is done purposefully to utilize the virtual thread’s ability to block:
@Incoming("tx")
@Outgoing("frauds")
@RunOnVirtualThread
public Fraud detect(Transaction tx) {
String key = "account:transactions:" + tx.account;
// Add sample
long timestamp = tx.date.toInstant(ZoneOffset.UTC).toEpochMilli();
timeseries.tsAdd(key, timestamp, tx.amount, new AddArgs()
.onDuplicate(DuplicatePolicy.SUM));
// Retrieve the last sum.
var range = timeseries.tsRevRange(key, TimeSeriesRange.fromTimeSeries(),
// 1 min for demo purpose.
new RangeArgs().aggregation(Aggregation.SUM, Duration.ofMinutes(1))
.count(1));
if (!range.isEmpty()) {
// Analysis
var sum = range.get(0).value;
if (sum > 10_000) {
Log.warnf("Fraud detected for account %s: %.2f", tx.account, sum);
return new Fraud(tx.account, sum);
}
}
return null;
}If you run this application and have a burst of transactions, it will not work. The processing is correctly executed on virtual threads. However, the Redis connection pool has not been tuned to handle that concurrency level. Very quickly, no Redis connections are available, and it starts enqueuing the commands into a waiting list. When this queue is full, it starts rejecting the commands. Fortunately, you can configure the max size of the waiting queue with:
# Increase Redis pool size (and waiting queue size) as we will have a lot of concurrency
quarkus.redis.max-pool-size=100 # Number of connection in the pool
quarkus.redis.max-pool-waiting=10000 # Waiting queue max sizeWhile we use Redis in this application, you will face identical problems with many other clients (including HTTP clients). So, configure them properly to handle this new level of concurrency.
If you run the application and open the UI, you will see that the concurrency reached a maximum of 1024, as expected.
A note about pinning and monopolization
Our messaging connectors have been tailored to avoid pinning. It is also the case for the Quarkus Redis client. Thus, this application does not pin the carrier thread.
But pinning is not the only problem that can arise. While virtual threads can be appealing, you must be careful not to monopolize the carrier thread. If, for example, you implemented a complex and CPU-intensive detection algorithm instead of relying on Redis, you would likely monopolize the carrier thread, defeating the purpose of virtual threads. It will force the JVM to create new carrier threads, ultimately increasing memory usage. The JVM will limit the number of created carrier threads. When this happens, your application will under-perform as your tasks will be enqueued until a carrier thread is available.
Summary
This post explains how you can execute message processing on virtual threads. While the example uses Kafka, you can use the same approach with the other messaging connectors provided by Quarkus. Do not forget that such kind of application:
-
requires tuning connection pools, as the concurrency is much higher than before
-
can lead to monopolization if your processing is CPU-intensive