Kafka - When to commit?

In a previous blog post, we have looked at failure strategies provided by the Reactive Messaging Kafka connector. But, imagine it’s our lucky day, and for once it worked. We should inform Kafka that the processing succeeded. In Kafka terminology, we call this: offset commit. This post covers the different strategies to commit offsets with the Reactive Messaging Kafka connector.
Kafka Consumer Group and Offsets
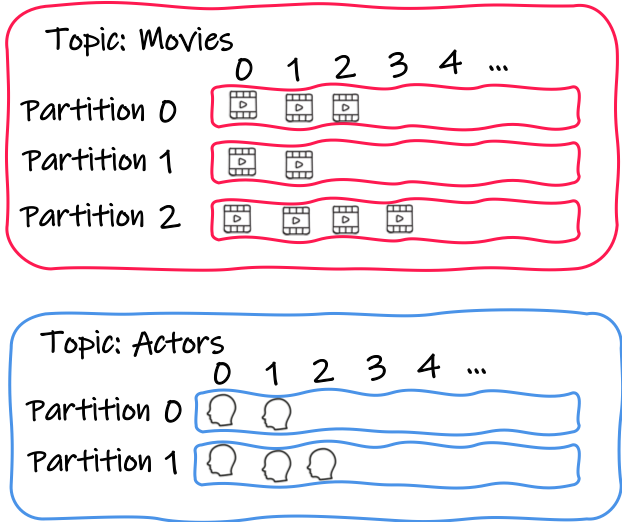
Kafka organizes records (i.e. messages) around topics. Each topic has a name, and applications send records to topics and poll records from topics. So far, nothing out of the ordinary.
Topics are divided into partitions.
Each partition is an ordered, immutable sequence of records.
Sending a message to a topic appends it to the selected partition.
Each message from a partition gets a sequential id number called offset.
It uniquely identifies each message within the partition.
So, with Kafka, you can identify an individual record using a <topic, partition, offset> tuple.
When an application consumes messages from Kafka, it uses a Kafka consumer.
With this consumer, it polls batches of messages from a specific topic, for example, movies or actors.
Retrieved messages belong to partitions assigned to this consumer.
And that aspect is essential.
Consumers belong to a consumer group, identified with a name (A and B in the picture above).
A group contains one or more consumers.
In general, when you scale up your application, it creates a consumer joining the same group.
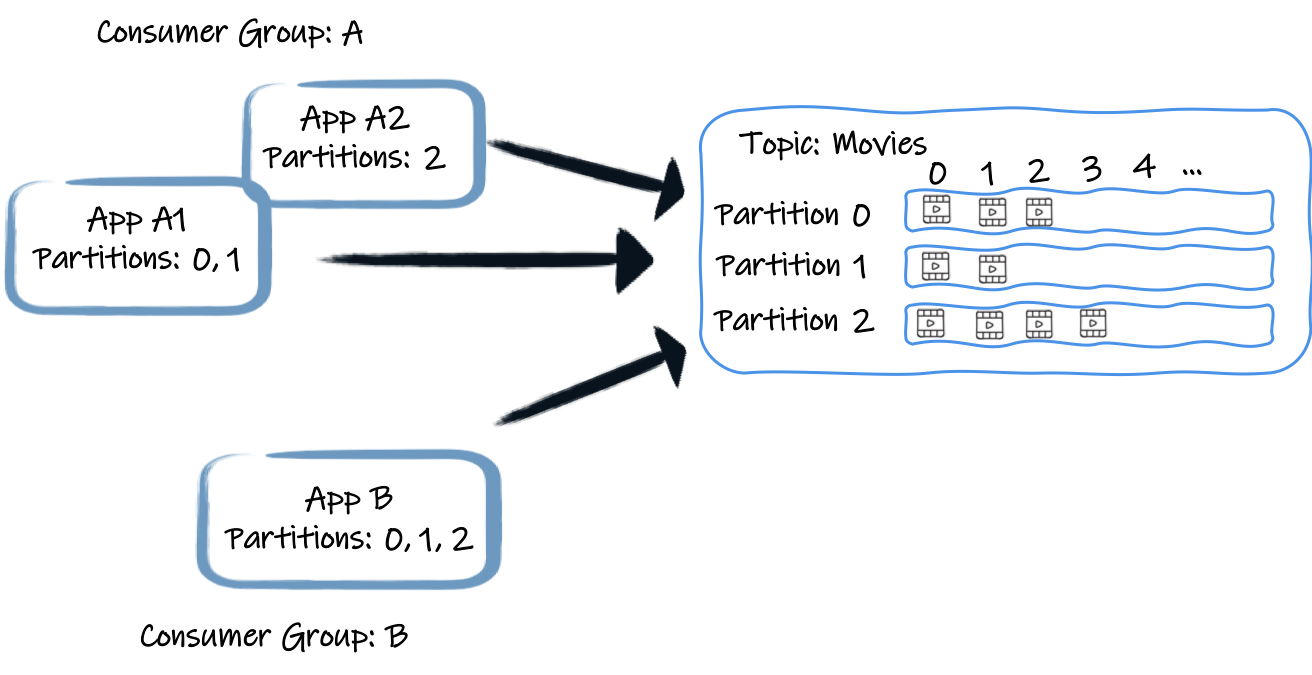
Each consumer group receives each record from a topic once. To achieve this, it assigns each consumer from a group to a set of partitions. For example, in the above picture, the consumer from the application A1 receives the records from the partitions 0 and 1. A2 receives the records from the partition 2. App B is the only consumer from its consumer group. So, it gets the records from all three partitions. Consequently (ignore rebalance or other subtilities for now), each record from a topic is only received once per consumer group, by a specific consumer from that group.
To orchestrate each consumer group’s progress, each consumer periodically informs the broker of its current position - the last processed offset. It commits the offset, indicating that all the previous records from that partition have been processed. So, if a consumer stops and comes back later, it restarts from the last committed position (if assigned to that partition again). Note that this behavior is configurable.
What’s important to notice is the periodic aspect of the commit. Offset commit is expensive, and to enhance performance, we should not commit the offset after each processed record. In this regard, Kafka behaves differently from traditional messaging solutions, such as JMS, which acknowledges each message individually. Another important characteristic is the positional aspect of the commit. You commit the position indicating that all the records located before that position are processed. But is it really the case?
The Kafka default behavior
The Apache Kafka consumer uses an auto-commit approach by default. Applications using such a consumer are structured around a polling loop:
while(true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(10000));
processRetrievedRecords(records);
}Such a program polls a batch of records, processes them, and then polls the next set.
While calling the poll method, the consumer periodically commits the last offset of the previous batches transparently.
Quite nice, right?
If the application fails to process a message, it throws an exception, which either interrupts the while loop or is handled gracefully (within the processRetrievedRecords method).
In the first case, it means that it won’t commit anymore (as it happens in the poll method, not called anymore).
If the application restarts, it resumes from the last committed offset (or apply the auto.offset.reset strategy, defaulting to latest, if there are no offsets for this group yet).
It may re-process a set of messages (it’s the application’s responsibility to handle duplicates), but at least nothing is lost.
So, is there anything wrong with this? Looks wonderful… until you add a pinch of asynchrony.
What if the message’s processing is asynchronous
If the message processing is asynchronous (offloaded to another thread, use non-blocking I/O…), failures may not interrupt the while loop from above.
Failure happens asynchronously, outside the polling thread.
If the poll method gets called again despite a failed processing, and auto-commit is still enabled, we may commit offsets while something wrong happened.
If some processing of previously retrieved records is not completed yet, while this auto commit happens, it may consider the record as processed correctly, but the outcome is unknown at that point.
So to handle these case, we can disable the auto-commit and switch to manual commit. In this case, it’s the application’s responsibility to commit the offsets regularly. So, the application needs to track the polled records, their processing, failures, and periodically commits the offsets. It might not look too tricky, but actually, it can become quite challenging. Again, in asynchronous scenarios, you may complete the processing of messages in various orders. For example, if you call a remote service for each record, the responses may not come in the same orders as the records. You need to track messages individually and only commit the offsets if all the previous messages are processed successfully. Without this, you may commit offsets while there is processing from previous records still in progress or even failed processing.
What can we do about this?
Kafka connector commit strategies
When using Reactive Messaging and the Kafka connector, you entered an asynchronous world.
Message processing may not happen synchronously and sequentially.
When a Reactive Messaging Message processing completes, it acknowledges the message.
In the case of processing failures, it sends a negative acknowledgment.
The Kafka connector receives these acknowledgments and can decide what needs to be done, basically: to commit or not to commit.
You can choose among three strategies:
-
throttled (default starting Quarkus 1.10)
-
latest (default before Quarkus 1.10)
-
ignore (default if
enabled.auto.commit=trueis set)
This is configured using the commit-strategy attribute:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.commit-strategy=throttledThe throttled strategy
The throttled strategy can be seen as an asynchronous variant of the default "auto-commit" behavior described above. When enabled, the connector tracks each received message and monitors their acknowledgment. When the connector finds out that all messages before a position are processed successfully, it commits that position. This commit happens periodically to avoid committing too often.
This strategy provides very good throughput and can handle asynchronous processing. To enable this strategy configures the channel with:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.commit-strategy=throttledThere is one detail to mention.
If an old message is neither acked nor nacked, the strategy cannot commit the position anymore.
It will enqueue messages forever, waiting for that missing ack to happen.
It can lead to out of memory, as the connector would never be able to commit a position and to clear the queue.
Fortunately, the strategy detects this situation and reports a failure to the connector, marking the application unhealthy.
The throttled.unprocessed-record-max-age.ms attribute configures the deadline for each message to be acked or nacked before being considered as a poison pill (Default is 1 minute).
The Ignore strategy
The connector uses this strategy by default if you explicitly enabled Kafka’s auto-commit (with the enable.auto.commit attribute set to true).
In this case, the connector ignores acknowledgment and won’t commit the offsets.
The Kafka consumer commits the offset periodically when polling batches, as described above.
This strategy works well if the message processing is synchronous and failures handled gracefully.
You can enable this strategy by configured enabled-auto-commit to true:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.enable.auto.commit=true| Be aware that starting Quarkus 1.9, auto commit is disabled by default. So you need to explicitly enable it. |
If you don’t enable auto-commit, using this strategy is still possible but will never commit the offsets. In other words, you would restart from the oldest stored records every time. While there are use cases for this, double-check that’s what you want. In this case, enable this strategy with:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.commit-strategy=ignoreThe latest strategy
This strategy commits the offset every time a message is acknowledged. This strategy tends to commit often, and so decrease the throughput. However, it also reduces the risk of duplicates if the messages are processed synchronously.
Enable this strategy with:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.commit-strategy=latest解决方案
In general, use the throttled strategy.
It provides high-throughput and handles the asynchronous use cases.
This strategy is becoming the default strategy in Quarkus 1.10.
You can also switch to the ignore strategy if the Kafka auto-commit is acceptable for you, or if you want to skip offset commit altogether.
That concludes this blog post. The next one will discuss how to receive and produce Cloud Events using the Kafka connector.