Building Kafka Streams applications with Quarkus and Eclipse MicroProfile

Kafka Streams is a very popular solution for implementing stream processing applications based on Apache Kafka. It lets you do typical data streaming tasks like filtering and transforming messages, joining multiple Kafka topics, performing (stateful) calculations, grouping and aggregating values in time windows and much more.
Unlike other streaming query engines that run on specific processing clusters, Kafka Streams is a client library. This means a (Java) application is needed which starts and runs the streaming pipeline, reading from and writing to the Apache Kafka cluster.
In this blog post we’ll discuss how the combination of Quarkus and Eclipse MicroProfile is a great foundation for implementing Kafka Streams applications, running on the JVM and as native code compiled ahead of time via GraalVM.
The Quarkus extension for Kafka Streams
As of version 0.17.0, Quarkus comes with an extension for building Kafka Streams applications. To create a new Quarkus project with this extension, run the following:
mvn io.quarkus:quarkus-maven-plugin:0.17.0:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=kafka-streams-quickstart-example \
-Dextensions="kafka-streams"This will set up a new project, adding the dependency to the Quarkus Kafka Streams extension, which in turn will pull in Kafka Streams and all its dependencies.
If you’ve worked with Kafka Streams before, the implementation of a data streaming pipeline will look very familiar to you.
You first build up a Topology and then create a KafkaStreams instance.
For starting and stopping the latter, Quarkus' StartupEvent and ShutdownEvent classes come in handy.
Overall, the structure of a Kafka Streams pipeline running on Quarkus will look like so:
@ApplicationScoped
public class MyStreamingPipeline {
private KafkaStreams streams;
void onStart(@Observes StartupEvent event) {
// set up Kafka Streams config, e.g. sourced from application.properties
Properties props = new Properties();
// props.put(..., ...);
// set up the stream topology
StreamsBuilder builder = new StreamsBuilder();
// builder.stream(...)
streams = new KafkaStreams(builder.build(), props);
streams.start();
}
void onStop(@Observes ShutdownEvent event) {
streams.close();
}
}For the very common requirement that you’d like to serialize and deserialize Java types used in the streaming pipeline into/from JSON
(e.g. when materializing them in a state store),
the Quarkus Kafka Streams extension provides the class io.quarkus.kafka.client.serialization.JsonbSerde.
It’s a Serde implementation based on JSON-B:
...
JsonbSerde<WeatherStation> weatherStationSerde = new JsonbSerde<>(WeatherStation.class);
GlobalKTable<Integer, WeatherStation> stations = builder.globalTable(
"weather-stations",
Consumed.with(Serdes.Integer(), weatherStationSerde)
);
...以本机可执行文件运行
Based on Kafka’s notion of topic partitioning, Kafka Streams applications can easily be scaled out: the load will be shared amongst multiple instances of the application, each processing just a subset of the partitions of the input topic(s).
Running Quarkus applications in native code via GraalVM comes in very handy for that: besides the very fast start-up time, the applications will use significantly less memory when compiled to native code. This lets you spin up many instances of a Quarkus-based Kafka Streams pipeline in parallel, in a very memory-efficient way.
The extension takes care of everything needed for building native Kafka Streams applications,
for instance it makes sure that the right RocksDB native libraries are added to the application image.
All you need to do is to specify the enableJni option for the Quarkus Maven plug-in,
allowing those native libraries to be invoked via JNI:
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>native-image</goal>
</goals>
<configuration>
<enableJni>true</enableJni>
</configuration>
</execution>
</executions>
</plugin>When using the JsonbSerde for unmarshalling JSON into corresponding Java objects,
those types must be marked with the @RegisterForReflection annotation,
so that they can to be instantiated reflectively by JSON-B in native mode:
@RegisterForReflection
public class WeatherStation {
public int id;
public String name;
}Then build the application using the native profile
(note this requires GraalVM to be installed on your system; refer to the Quarkus native image guide to learn more):
mvn clean package -f aggregator/pom.xml -PnativeFinding the right amount of memory needed for running the application can require some testing.
E.g. observe CPU load and run the native binary with the -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+VerboseGC options
in order to gain insight into how often garbage collection kicks in.
If you started the application with not enough heap space,
you’ll typically observe that GC is happening very frequently, causing increased CPU load.
To give an example, for the streaming pipeline discussed in the Kafka Streams extension guide,
a heap size of 32 MB (-Xmx32m) works very well,
resulting in less than 50 MB memory needed by the process in total
(RSS, resident set size).
Note that this number also contains the memory needed for the HTTP endpoint defined in that example,
which is used for answering interactive queries via REST.
Gaining Operational Insight
One of the nice things about Quarkus is that it comes with support for all the Eclipse MicroProfile APIs. They help to address common requirements when building microservices, such as health checks ("Is my application running and ready to handle requests?") and metrics ("What’s the throughput of my application?", "How many requests has it processed?" etc.).
Based on those APIs, it just requires a little bit of coding to implement health checks and metrics for a Kafka Streams application. You can add the right dependencies by running:
./mvnw quarkus:add-extension -Dextensions="health,metrics"Healthchecks
Then creating the health check is as simple as adding the following to the pipeline implementation:
@Liveness
@ApplicationScoped
public class MyStreamingPipeline implements HealthCheck {
private KafkaStreams streams;
// ...
@Override
public HealthCheckResponse call() {
return HealthCheckResponse.named("My Pipeline")
.state(streams.state().isRunning())
.build();
}
}This will expose a health check via HTTP under /health/live,
which when queried will yield a response like this:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 144
Content-Type: application/json;charset=UTF-8
Date: Wed, 26 Jun 2019 10:08:36 GMT
{
"checks": [
{
"name": "My Pipeline",
"status": "UP"
}
],
"status": "UP"
}When using a container orchestrator such as Kubernetes, you could then set up a liveness probe for this endpoint. If the health check fails (i.e. the streaming pipeline is not in the running state), it will return an HTTP 503 response. This would be the indicator to the orchestrator to restart the pod of this application.
指标
While a health check provides simple means of finding out whether the application is in a state where it can handle requests/messages or not, it is desirable to have more insight into the behaviour of the service. E.g. it might be of interest to see how many messages have been processed by the streaming pipeline, what’s the arrival rate of messages, what’s the average processing time and much more.
Kafka Streams comes with rich metrics capabilities which can help to answer these questions. Using the MicroProfile Metrics API, these metrics can be exposed via HTTP. From there they can be scraped by tools such as Prometheus and eventually be fed to dashboard solutions such as Grafana. Note that exposing metrics via HTTP instead of JMX has the advantage that this also works when running the application in native mode via GraalVM.
Similar to the health check case, just a bit of glue code is needed for exposing the metrics:
@ApplicationScoped
public class MyStreamingPipeline {
@Inject
MetricRegistry metricRegistry;
private KafkaStreams streams;
void onStart(@Observes StartupEvent event) {
// ...
streams.start();
exportMetrics();
}
// ...
private void exportMetrics() {
Set<String> processed = new HashSet<>();
for (Metric metric : streams.metrics().values()) { (1)
String name = metric.metricName().group() +
":" + metric.metricName().name();
if (processed.contains(name)) {
continue;
}
// string-typed metric not supported
if (name.contentEquals("app-info:commit-id") || (2)
name.contentEquals("app-info:version")) {
continue;
}
else if (name.endsWith("count") || name.endsWith("total")) { (3)
registerCounter(metric, name);
}
else {
registerGauge(metric, name); (4)
}
processed.add(name);
}
}
private void registerGauge(Metric metric, String name) {
Metadata metadata = new Metadata(name, MetricType.GAUGE);
metadata.setDescription(metric.metricName().description());
metricRegistry.register(metadata, new Gauge<Double>() {
@Override
public Double getValue() {
return (Double) metric.metricValue();
}
} );
}
private void registerCounter(Metric metric, String name) {
// ...
}
}| 1 | Process all Kafka Streams metrics, using a unique name to register them |
| 2 | Some string-typed "metrics" must be excluded |
| 3 | All metrics whose name ends with "total" or "counter" will be exposed as counter-typed metrics |
| 4 | All other metrics will be exposed as gauge-typed metrics, i.e. plain numeric values |
Once the application is started, the metrics will be exposed under /metrics,
returning the data in the OpenMetrics format by default:
# HELP application:stream_metrics_process_total The total number of occurrence of process operations.
# TYPE application:stream_metrics_process_total counter
application:stream_metrics_process_total 2866.0
# HELP application:stream_metrics_poll_latency_avg The average latency of poll operation.
# TYPE application:stream_metrics_poll_latency_avg gauge
application:stream_metrics_poll_latency_avg 83.3135593220339
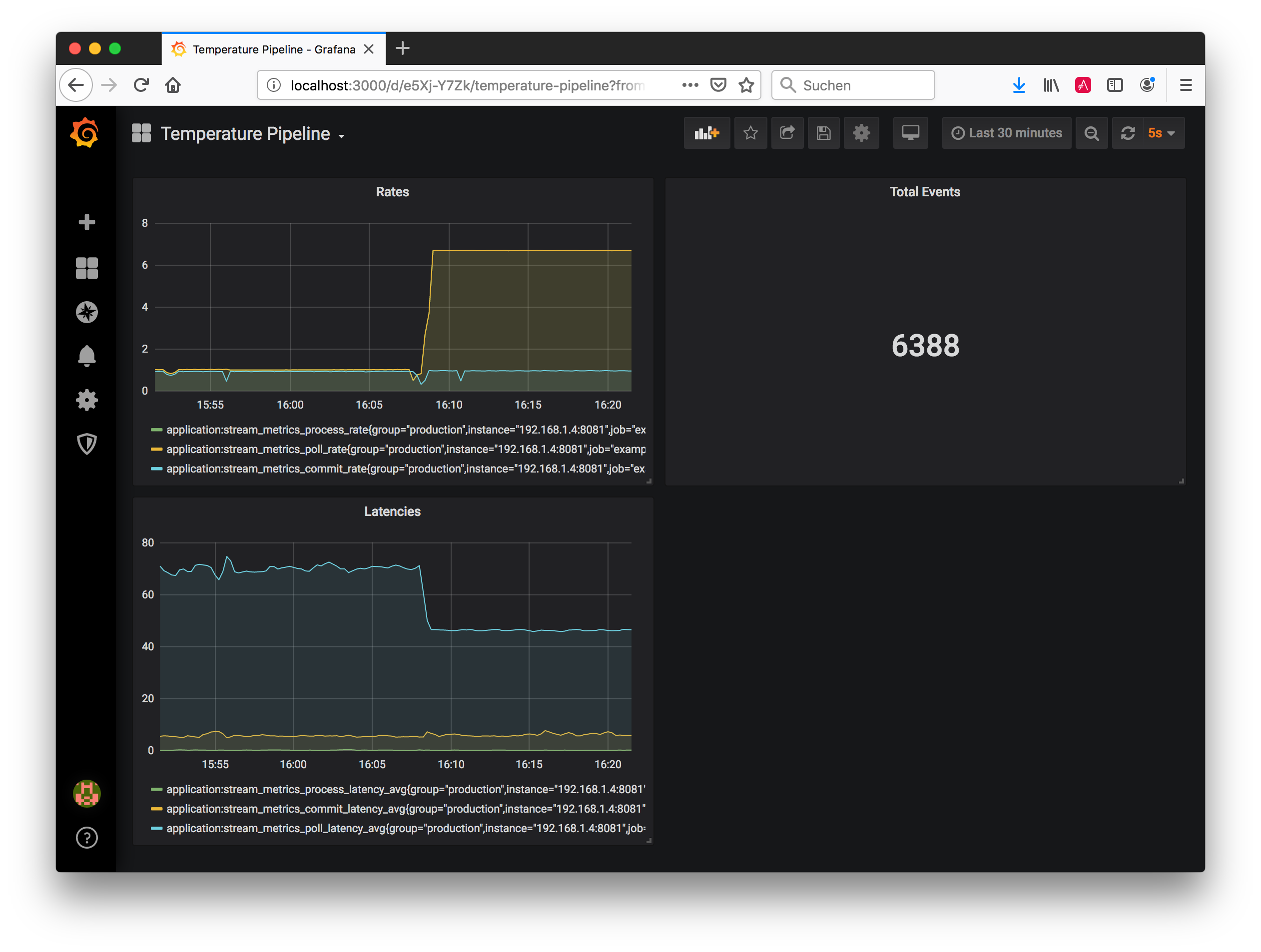
# ...From here it’s a matter of minutes to set up Prometheus to scrape this target, configure a Prometheus data source in Grafana and configure a dashboard for visualizing the metrics of interest to you. E.g. the following shows a simple dashboard displaying the poll/process/commit rates and latencies as well as the total number of processed events in the quickstart example:
Summary and Outlook
Quarkus and Eclipse MicroProfile are a great basis for building Kafka Streams applications. The Quarkus extension for Kafka Streams comes with everything needed to run stream processing pipelines on the JVM as well as in native mode via GraalVM. The MicroProfile APIs for health checks and metrics can be used to expose the right information for gaining insight into running stream processing applications.
Going forward, we plan to further reduce the efforts needed for building Kafka Streams applications on Quarkus.
Instead of having to deal with the lifecycle of the pipeline yourself,
it should be enough to declare a CDI producer method returning the streaming Topology:
@Produces
public Topology buildTopology() {
// set up the stream topology
StreamsBuilder builder = new StreamsBuilder();
// builder.stream(...)
return builder.build();
}This means you’ll be able to focus on implementing the actual pipeline logic,
while the Quarkus extension would take care of everything else:
configuring Kafka Streams based on the Quarkus application.properties file,
starting the pipeline and automatically exposing healthchecks and metrics.
In case this sounds interesting to you, have an eye on the next Quarkus release announcements, as this improved functionality should be out soon. If you got any related ideas, let us know and join the discussion in Quarkus issue #2863.
To learn more about the Quarkus extension for Kafka Streams and its current capabilities, check out the detailed guide. It not only discusses the actual stream pipeline implementation, but also touches on building (distributed) interactive queries for exposing the current processing state via REST.